Leyendo la entrada de Bruno sobre la librería kseq.h me entraron ganas de recopilar en el blog unos valiosos comandos de Linux que nos pueden ayudar a salvar mucho tiempo al trabajar con millones de secuencias de NGS.
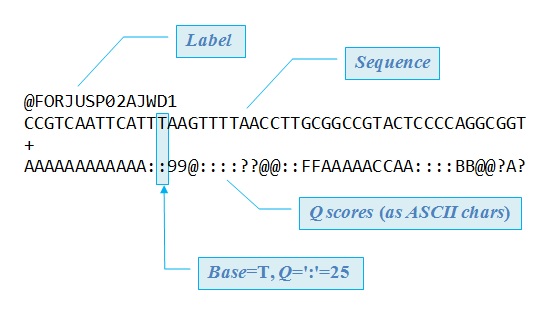
Leyendo la entrada de Bruno sobre la librería kseq.h me entraron ganas de recopilar en el blog unos valiosos comandos de Linux que nos pueden ayudar a salvar mucho tiempo al trabajar con millones de secuencias de NGS.Un fichero con extensión '.fq.gz' es un fichero en formato FASTQ comprimido en formato GZIP. Los ficheros FASTQ con datos de los nuevos métodos de secuenciación (NGS) suelen ocupar decenas de Gigabytes de espacio de disco (una cantidad indecente para la mayoría de los mortales) y comprimidos con GZIP se reducen (mucho más que con el clásico ZIP).
A continuación se mostrarán los comandos para manejar ficheros FASTQ comprimidos, pero con unas leves modificaciones podrán también procesar ficheros FASTQ sin comprimir (no recomendado), por ejemplo cambiando 'zcat' por 'cat'. También se pueden modificar para procesar ficheros FASTA comprimidos y sin comprimir.
Para empezar, vamos a comprimir en formato GZIP un archivo FASTQ:
> gzip reads.fq
El fichero resultante se llamará por defecto 'reads.fq.gz'.
Nos puede interesar conocer cuanto espacio ocupa realmente un archivo 'fq.gz' comprimido, para ello usaremos el mismo comando 'gzip':
> gzip --list reads.fq.gz
compressed uncompressed ratio uncompressed_name
18827926034 1431825024 -1215.0% reads.fq
Parece que GZIP en vez de comprimir expande, pero no es verdad, simplemente que la opción '--list' de 'gzip' no funciona correctamente para archivos mayores de 2GB. Así que hay que recurrir a un método más lento y esperar unos minutos:
> zcat reads.fq.gz | wc --bytes
61561367168
Si queremos echar un vistazo al contenido del archivo podemos usar el comando 'less' o 'zless':
> less reads.fq.gz
> zless reads.fq.gz
Y para saber el número de secuencias que contiene simplemente hay que contar el número de líneas y dividir por 4 (le costará unos minutos):
> zcat reads.fq.gz | echo $((`wc -l`/4))
256678360
Contar el número de secuencias en un fichero FASTA:
> grep -c "^>" reads.fa
Podemos contar cuántas veces aparece una determinada secuencia, por ej. ATGATGATG:
> zgrep -c 'ATGATGATG' reads.fq.gz
398065
> zcat reads.fq.gz | awk '/ATGATGATG/ {nlines = nlines + 1} END {print nlines}'
398065
O extraer ejemplos de dicha secuencia:
> zcat reads.fq.gz | head -n 20000 | grep --no-group-separator -B1 -A2 ATGATGATG
en ficheros FASTA:
> zcat reads.fa.gz | head -n 10000 | grep --no-group-separator -B1 ATGATGATG
A veces nos interesará tomar un trozo del fichero para hacer pruebas, por ejemplo las primeras 1000 secuencias (o 4000 líneas):
> zcat reads.fq.gz | head -4000 > test_reads.fq
> zcat reads.fq.gz | head -4000 | gzip > test_reads.fq.gz
O extraer un rango de líneas (1000001-1000004):
> zcat reads.fq.gz | sed -n '1000001,1000004p;1000005q' > lines.fq
Para extraer 1000 secuencias aleatorias de un archivo FASTQ:
> cat reads.fq | awk '{ printf("%s",$0); n++; if(n%4==0) { printf("\n");} else { printf("X#&X");} }' | shuf | head -1000 | sed 's/X#&X/\n/g' > reads.1000.fq
O de un archivo FASTA:
> cat reads.fa | awk '{if ((NR%2)==0)print prev"X#&X"$0;prev=$0;}' | shuf | head -1000 | sed 's/X#&X/\n/g' > reads.1000.fa
También nos puede interesar dividir el fichero en varios más pequeños de por ejemplo 1 miĺlón de secuencias (o 4 millones de líneas):
> zcat reads.fq.gz | split -d -l 4000000 - reads.split
> gzip reads.split*
> rename 's/\.split(\d+)/.$1.fq/' reads.split*
Y posteriormente reunificarlos:
> zcat reads.*.fq.gz | gzip > reads.fq.gz
Algunos de estos comandos y otras ideas pueden consultarse en:
http://darrenjw.wordpress.com/2010/11/28/introduction-to-the-processing-of-short-read-next-generation-sequencing-data/
Podéis ayudarme a completar el post escribiendo vuestros comandos más útiles en comentarios...